© 2023 yanghn. All rights reserved. Powered by Obsidian
9.2 长短期记忆网络(LSTM)
要点
- 和 GRU 的思想一致,通过
和 来控制过去的信息和当前的信息比重,最后 来控制记忆 的输出 ,并转化到 之间方便训练,防止梯度爆炸 - 和 GRU,普通 RNN 不同的是,状态有两个(
和 )
和 9.1 门控循环单元(GRU) 思想类似,LSTM 提出时间更早
1. 输入门、忘记门和输出门
和 9.1 门控循环单元(GRU)一样,但 LSTM 有三个门:
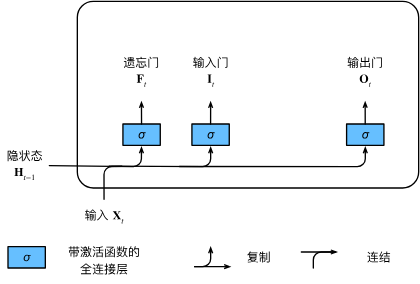
我们来细化一下长短期记忆网络的数学表达。假设有
其中
2. 候选记忆元
实际上就是 rnn 里面的状态:
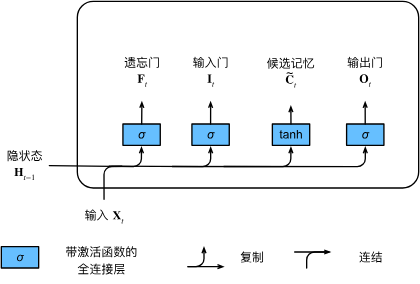
3. 记忆元
与 GRU 更新门类似,控制有多少之前的状态需要记住:
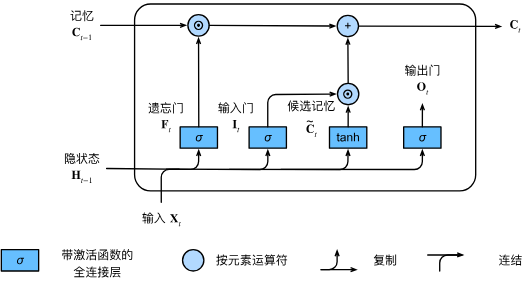
- 和普通 RNN 不一样,这里还输出了记忆
,输入的 是上一个时刻传进来的 - 不像 GRU 的更新门[[9.1 门控循环单元(GRU)#^f022e1]],GRU会把状态凸组合继续限定到(0,1),如果LSTM 这里如果直接输出
当做隐藏状态,这个值随着时间步增加范围会越来越大,所以还需要输出门对记忆进行 normalize
4. 输出门
这里确保了
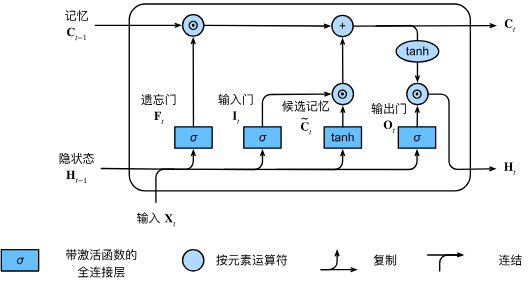
5. 三个门总结
LSTM 中间有三个状态相关的参数:
控制多少原来的状态被忘记 控制多少现在的状态输入出去 控制下一个状态是否要重置为 0
6. 从 0 开始实现 LSTM
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
6.1 初始化模型
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
6.2 定义模型
和 GRU 不一样的是,这里的模型输入输出的状态有
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
按照上面定义实现,和 GRU 类似
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
6.3 训练与预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
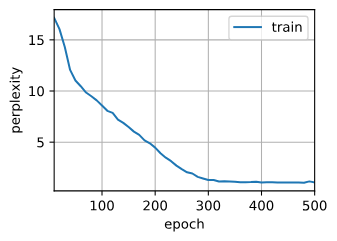
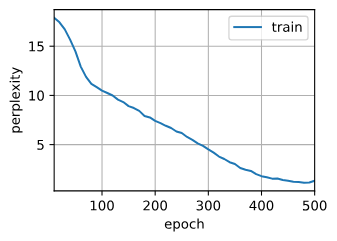
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.3, 17736.0 tokens/sec on cuda:0
time traveller for so it will leong go it we melenot ir cove i s
traveller care be can so i ngrecpely as along the time dime
6.4 简洁实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.1, 234815.0 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby